Should You Use a Stateful Streaming Framework?


With the rise of big data in the last decade the industry has adopted the tools to process it. In the past, data was often processed using batch jobs. Later, companies started to move to map/reduce frameworks like Spark. These days, a lot of data is processed using distributed logs like Kafka.
Kafka has proven itself as a reliable but fairly low-level way to process data. So engineers have been looking for higher-level abstractions that allow easier data processing on top of Kafka. Enter the world of stateful streaming frameworks: Apache Flink, Kafka Streams, Apache Samza and others. These tools allow you to join and fork multiple streams and do stateful processing like aggregation. For example, if you have an e-commerce website that produces a stream of orders, you can calculate the totals for each customer without a database.
These frameworks promise a set of useful benefits, such as exactly one processing, windowing, queriable state, testability, high availability and resiliency. Kafka Streams, for example, states that it is "The easiest way to write mission-critical real-time applications and microservices". Do these tools deliver on their promises?
Streaming Framework Architecture
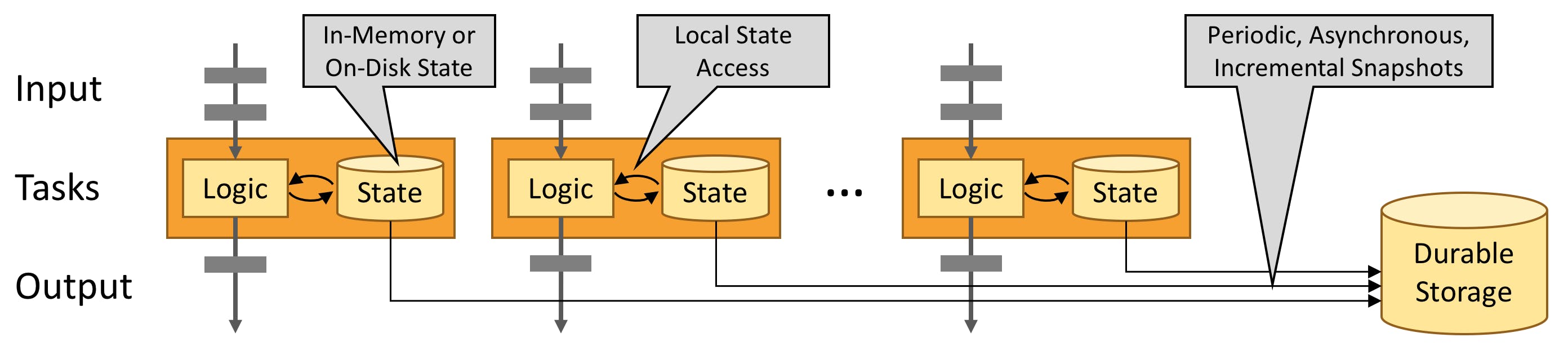
Most of these frameworks have a small cluster of job manager nodes and a larger cluster of worker (task manager) nodes. The job managers decide how to spread the workload across the worker nodes. Each worker node is responsible for processing data, e.g. consuming messages from a set of Kafka topic-partitions, doing some calculations and writing the results to another Kafka topic.
The statefulness is achieved by operating a local database such as a RocksDB instance on each worker node. The framework allows the workload to read and write keyed values to the database.
To achieve high availability, the framework needs to take snapshots of each database instance regularly, called checkpointing. This allows it to resume processing from a recent point instead of the beginning of time.
Operating Streaming Frameworks in the Real World
I have used both Kafka Streams and Apache Flink in commercial environments. Kafka Streams was used in a real-time backend service that would handle its write APIs by sending client requests through a set of streams that would use the state for request validation (e.g., ensuring the unique key does not already exist). After the validation succeeds, it would write the result to the output Kafka topic that would be projected to a RocksDB instance used to serve the read requests. This use case had strict latency requirements (tens of milliseconds).
Flink was primarily used in a data pipeline to discard duplicate data pieces. That is, the Flink workload would read data from 2 Kafka streams, check the current state and discard the payload if it had been already present. Otherwise, it would write it to the output stream. The latency requirements of the pipeline were quite loose - in the order of minutes.
Below are some of the lessons learned from operating these real-world systems.
Streaming Frameworks Aren't for Real-Time Use Cases
Due to their design, streaming frameworks can only make progress when all worker nodes are healthy. Whenever one node goes down, the world stops and no progress is made. As you can imagine, this is a problem as computers do go down, and for many reasons. E.g., your infrastructure team or your cloud provider may have NLA workflows to install updates. Nodes also go down when you deploy a new version of the service. When a node goes down, the framework will try to reassign the work to other nodes (rebalancing). This is no small feat as the new worker needs to have the state, which requires having the database with the state populated. Rebalancing takes time, and while it is happening your latency goes through the roof and your Kafka topics are building lag causing the monitors to alert. Yikes!
There are things you can do to make rebalancing happen faster. With Kafka Streams, you can configure standby replicas. In Flink, you can (and, likely, should) set up "high availability". This doesn't mean rebalancing will happen within your SLAs though. It probably won't, which means you should only use these frameworks for non-critical, asynchronous use cases with a high tolerance for delays. Like data analytics.
They Are Brittle
A node going down is not the only thing that can prevent your system from making progress. It can also happen for other reasons - for example, if checkpointing does not succeed. In Flink, checkpointing is critical; without it, the framework has to start processing from the beginning of time. Why would the checkpointing fail? There are many reasons depending on how it is configured. If you set it to save to S3 it may time out due to a large size or get throttled by AWS due to too many requests writing to one bucket.
They Are Complex
Look at the configuration parameters of the framework you are planning to use and ask yourself if you have the time and resources to comprehend at least some of them. You may assume the configuration has sane defaults but practice shows many of the values depend on your workload.
It Is Hard To Make Changes
This is another consequence of the stateful design. The saved state has to have the details of the topology. It needs to store some of the configuration parameters like the max parallelism in Flink. All this means you will likely want to have a shadow cluster in each of your production environments to let you roll out changes there first and use its state to speed up the deployment to the main one.
In any case, this is more resources, more complexity and hence more money spent.
Other Issues
The above is not a comprehensive list by any means. Other issues include the lack of autoscaling support and unbalanced workloads (where some task manager nodes are much busier than the rest) to name a few.
Conclusion
Pay little attention to vendors' marketing materials, they are mostly fluff. Instead, verify each promise. I suggest only using stream processing frameworks for non-critical use cases like data analytics. If you do decide to introduce these tools to your stack, make sure you do these before:
build a proof of concept
load test with the expected max production load, and then 10x of that
deploy and observe the latency, lag and other metrics
run game days