


In the last blog post, I wrote about Go's channels with a demo of a data pipeline that buffers the input and flushes the buffer when it's full or after a certain amount of time passes. In this post, I will talk about how I tried to prioritize one of the branches in the select statement and how well it worked.
The example had a select statement like this:
for {
select {
case m, channelOpen := <-a.in:
if channelOpen {
// channel is open - flush only if the buffer is full
buffer = append(buffer, m)
if len(buffer) == a.bufferSize {
a.out <- buffer
buffer = make([]Message, 0)
}
} else { // todo channel closed - flush
return
}
case <-ticker.C:
// it's time to flush the buffer
if len(buffer) > 0 {
a.out <- buffer
buffer = make([]Message, 0)
}
}
}
If there is data in the input channel it adds it to the buffer. If the buffer is full, it is flushed. When the timer ticks and there is some data in the buffer it is also flushed.
I was initially concerned that this approach would flush the buffer on a timer when there is no real need to do that. Meaning there is significant traffic but every time the timer is triggered it flushes an incomplete buffer thus increasing the number of flushes unnecessarily. This behavior would be due to the randomness of Go's blocking select statement, which tries to be fair and give all cases a chance to run.
When I came across a priority select implementation I thought it was a really good idea and decided to try it out. The above select statement became the two nonblocking ones within the same for loop with the first one taking priority. Note the default cases in both to prevent blocking. The idea here is that when there is data in the input channel a.in Go's runtime does not get to the second select at all.
for {
select {
case m, channelOpen := <-a.in:
if channelOpen {
// channel is open - flush only if the buffer is full
buffer = append(buffer, m)
if len(buffer) == a.bufferSize {
a.out <- buffer
buffer = make([]Message, 0)
}
} else {
// channel closed - flush
return
}
default: // do not block
}
select {
case <-ticker.C:
// it's time to flush the buffer
if len(buffer) > 0 {
a.out <- buffer
buffer = make([]Message, 0)
}
default: // do not block
}
}
The first problem with this implementation is that it is really hard if not impossible to unit-test the priority behavior. This is true for many things concurrency though.
But a bigger surprise was how the CPU profile of the service changed after deploying this change.
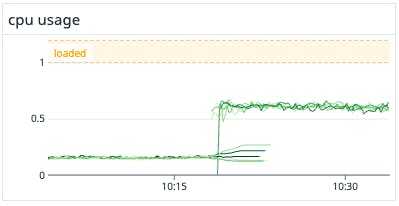
As you can see, processor consumption increased by about 2x. Here is what the Datadog Go profiler's Top Methods table showed.

So the profiler points to the runtime select implementation. And it makes total sense in hindsight as the only way to implement a non-blocking select is to loop and check all cases thus consuming 100% of the CPU. There is a good explanation of this behavior here.
So how do we make our select prioritize reading from the channel while also flushing on a timer when the traffic is low?
We can remember the time when the latest flushing was done and check it when the timer ticks. If the difference is lower than the threshold, we do nothing. But if enough time has passed we do flush.
for {
select {
case m, channelOpen := <-a.in:
if channelOpen {
buffer = append(buffer, m)
if len(buffer) == a.bufferSize {
a.out <- buffer
buffer = make([]Message, 0)
lastFlushed = time.Now()
}
} else { // todo flush
return
}
case <-ticker.C:
if time.Now().Sub(lastFlushed) >= flushTickerDuration && len(buffer) > 0 {
a.out <- buffer
buffer = make([]Message, 0)
lastFlushed = time.Now()
}
}
}
Conclusion
Be careful with non-blocking select statements as they may consume all available CPU. Prefer blocking selects and use Timer/Ticker to time out a blocking operation.